The first step when I start a new game (after I decide what opening variation to play), is to import from my Master IDeA tree, previous work done for the position I am working on.
 If I don’t have previous analysis work on an opening, or if the work done there is not good (old engine – bad quality), I start from scratch and I «seed» IDeA by adding variations in the notation pane (actually I would just follow some database tree and enter the most frequently played moves), or import positions as tasks from a tree by using a script I wrote (it’s on the Aquarium forum, but more on scripts later).
If I don’t have previous analysis work on an opening, or if the work done there is not good (old engine – bad quality), I start from scratch and I «seed» IDeA by adding variations in the notation pane (actually I would just follow some database tree and enter the most frequently played moves), or import positions as tasks from a tree by using a script I wrote (it’s on the Aquarium forum, but more on scripts later).Both approaches have advantages and disadvantages. The second one imports too many tasks to IDEA (for example 10K tasks would be a typical import) and in the alternatives phase of IDeA the same amount of alternative tasks would be generated (if 10K tasks were imported in the import stage, additional 10K would be generated at alternatives stage). If you don’t have a big computer with many cores (or many networked computers) this takes too much time to be feasible.
There is another problem with this approach is , if you are like me and limit the number of alternatives in the IDeA options , then IDeA will not generate enough new moves for a position from the engine, because there are already too many alternatives for the position.
The «by hand seed» on the other hand has its drawbacks too. IDeA gets to expand only some branches of theory and you have to «interact» much more, but on the bright side, you are actually watching how the evaluation evolves, if and when a move fails high or low and investigate more on that. Lately I am using more of that approach.
The biggest part of the research, that is not automated, is browsing the IDeA tree, discovering repeating patterns and trying to apply them in similar positions. This is a tedious process and I use another script I wrote for that (‘watchnodes’) which records the progress of some positions, how evaluations change and why, so I can review them later. Of course I make extensive use of Note lists in IDeA.

Figure 2, Notes Lists keep track of positions and your comments on them
Those are positions that you would like to remember (while you browse the tree). So if I find a position that I think needs more analysis later, I add it to the ‘interesting’ list, and add a comment next to it, so I can later remember my findings.
Notes are very important, at least for me because my memory is very poor.
The biggest problem with IDEA is ‘orphan’ nodes. I call those nodes that are the result of a prolongation task, that change the evaluation of a root node. For example you have a position that is +1.00 and a prolongation task (from a sub variation) adds a variation that ends in 0.00. This changes of course the evaluation of that root node to 0.00. If the evaluation is correct , there is no problem, but if its not, then you may «lose a promising variation» because of a single bad evaluation of an engine. That single node needs attention (and more analysis) and IDeA won’t do that for you (it would do it for you if the change of evaluation came from an alternative’s task, but not from a prolongation).
To solve that big problem I use my custom ‘watchnodes’ scripts. I watch how evaluations evolve and why and when they change, so when I return to my PC, I can see if something strange happened and analyse it.
Of course I use a lot of infinite analysis (with several engines). After a session of IDeA, I review the results using 4-5 engines running at the same time in Infinite analysis (this is actually why I love Aquarium. It managed to combine IDeA and Infinite Analysis in a single procedure). The IA session brings new ideas and adds new tasks in the IDeA queue and then an IDeA session follows and so on.

Figure 3, several engines analyzing and feeding positions to IDeA
My main goal is a) to avoid endgames and b) to enter complex positions.
Endgames are nowadays almost impossible to win. With the appearance of FinalGen, it’s now even more difficult than before and technical wins are almost impossible. Complex positions are the only way to play for a win.

Figure 4, Aquarium provides important statistics about IDeA projects
To handle complex positions I use the 3 statistics features of IDeA (2d Evaluation , MM-Delta and Branching). These are **very important** and anyone should master them and use them.
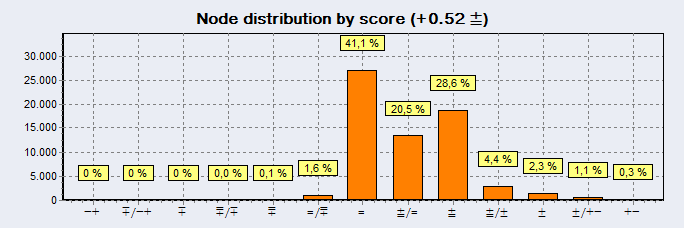
Figure 5, 2D-Evaluation of a position in an IDeA tree
2D- evaluation, helps you choose the position with most chances for a win. For example 2 moves have evaluation of 0.00, but the first one has a distribution skewed to the left and the other to the right. This means, that the first move has a lot of variations that favor black (not optimal ‘yet’) and the other favor white. For me that means, if I search enough on the first one, I might be able to improve a sub variation (or an idea in that) that favors black and make it principal variation. 2D-evaluation is the most important tool you have.

Figure 6, MM-Delta: Comparison of point evaluations and IDeA scores
MM-Delta just tells you how good the point evaluation (from IA analysis) is compared to IDeA evaluation. If there are many positions with big evaluation difference from point evaluation to minimaxed evaluation, that means that the engine has problems finding the best variations, and the position is dangerous. So if you want to win, enter such sub trees, with high probability of making mistakes (both you and the opponent). If you want to draw, just enter safe paths, where the engine is always spot on.
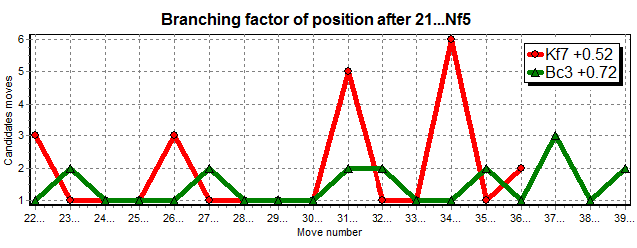
Figure 7, IDeA branching factor graph
Last but not least is the branching factor. You see there with a single graph, how much work you have to do to analyze the position. Big branching means a lot of work (many opportunities to discover new surprise moves or to go wrong). If you want complexity enter variations with high branching factor. If you want aim for simple games, enter variations with low branching factor and lower work load for you and your computer
to be continued…